#!/usr/bin/env python
# coding:utf8
# ++++++++++++description++++++++++++#
"""
@author:ying
@contact:1074020480@qq.com
@site:
@software: PyCharm
@file: 8_select_insert_shell_quick.py
@time: 2019/11/20 上午11:01
"""
# +++++++++++++++++++++++++++++++++++#
li = [5, 38, 15, 36, 26, 27, 2, 38, 4, 19, 44, 46, 50, 48, ] # 待排序数列
"""
选择排序(Selection Sort)也是一种简单直观的排序算法,其平均时间复杂度为O(n^2)。
唯一的好处算是不占用额外的内存空间。
算法步骤
1、首先在未排序序列中找到最小(大)元素,存放到排序序列的起始(末尾)位置;
2、再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾;
3、重复第二步,直到所有元素均排序完毕。
"""
def select_sort(li):
n = len(li) # n=15
for i in range(n - 1): # i=0-13
# 定位为最小值的索引
minIndex = i
for j in range(minIndex, n):
if li[j] < li[minIndex]:
# 如果当前的值小于之前定的最小值,则将最小值的索引进行替换
minIndex = j
# 实际最小值与当前值进行位置互换
li[i], li[minIndex] = li[minIndex], li[i]
select_sort(li)
插入排序
"""
插入排序(Insertion Sort)也是一种简单直观的排序算法。
其通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
其时间复杂度为O(n^2)。
该算法的好处是稳定。
算法步骤:
先将前两个排序
再将前三个排序
前四个
.......
一直到最末尾
"""
li = [5, 38, 15, 36, 26, 27, 2, 38, 4, 19, 44, 46, 50, 48, ] # 待排序数列
def insert_sort(li):
# 从第二个位置,即下标为1的元素开始向前插入
for i in range(1, len(li)):
# 从第i个元素开始向前比较,如果小于前一个元素,交换位置
for j in range(i, 0, -1):
if li[j] < li[j - 1]:
li[j], li[j - 1] = li[j - 1], li[j]
insert_sort(li)
print(li)
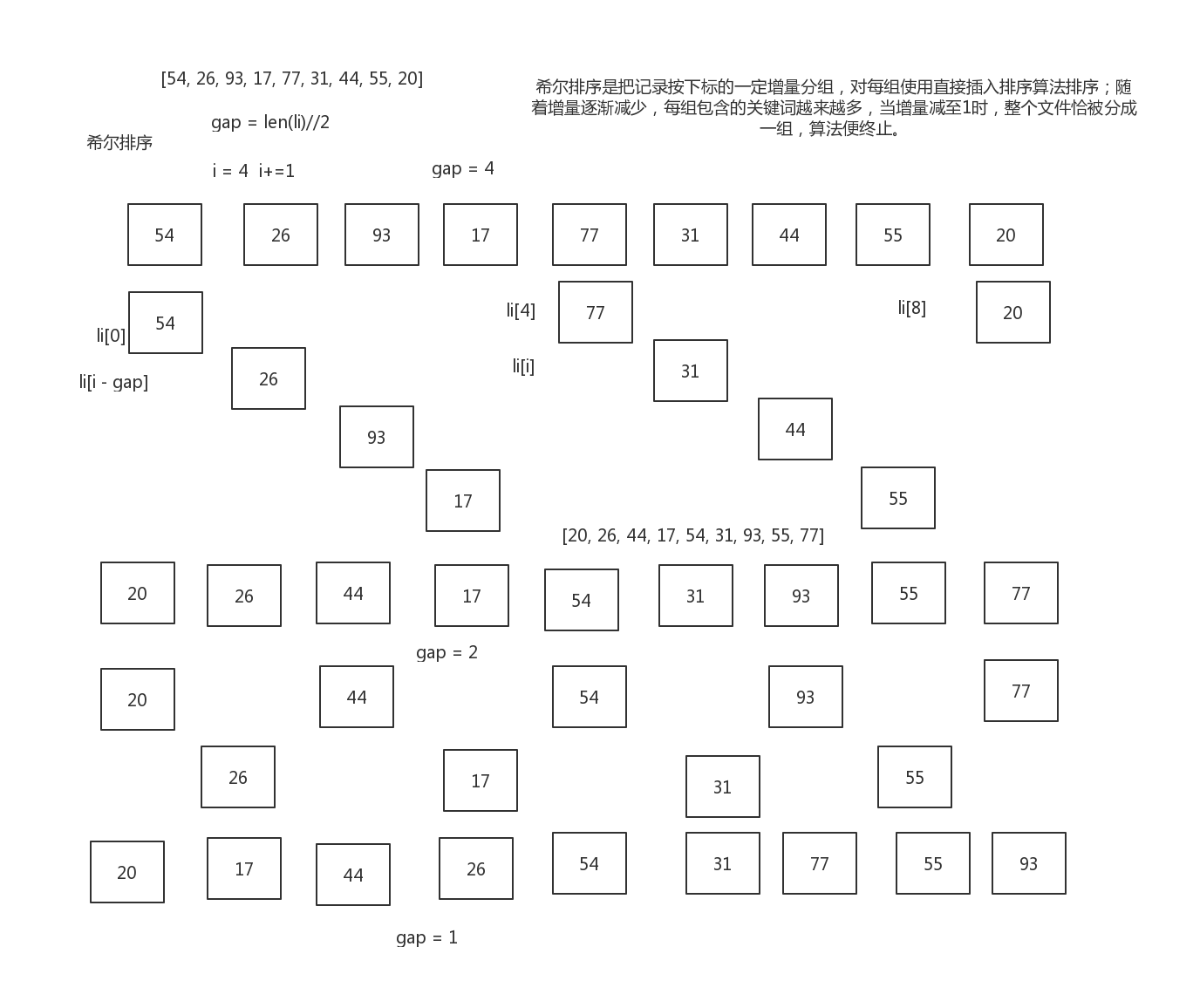
希尔排序
"""
如果当要排序数列是”5, 4, 3, 2, 1“的时候,此时我们将“无序块”中的记录插入到“有序块”时,
效率可想而知,因为插入排序每次只能将数据移动一位。
而希尔(Shell)于1959年根据这个弱点进行了算法改进,融入了一种叫做“缩小增量排序法”的思想。
其时间复杂度为O(n logn)
算法步骤
1、选择一个增量序列 t1,t2,……,tk,其中 ti > tj, tk = 1;
2、按增量序列个数 k,对序列进行 k 趟排序;
3、每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,
分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
希尔排序的基本思想是:将数组列在一个表中并对列分别进行插入排序,重复这过程,不过每次用更长的列(步长更长了,列数更少了)来进行。
最后整个表就只有一列了。将数组转换至表是为了更好地理解这算法,算法本身还是使用数组进行排序。
"""
li = [5, 38, 15, 36, 26, 27, 2, 38, 4, 19, 44, 46, 50, 48, ] # 待排序数列
def shell_sort(li):
n = len(li)
# 初始步长
gap = n // 2
while gap > 0:
# 按步长进行插入排序 4-8
for i in range(gap, n,):
# 插入排序
while i >= gap and li[i - gap] > li[i]:
li[i - gap], li[i] = li[i], li[i - gap]
i -= gap
# 得到新的步长
gap = gap // 2
shell_sort(li)
print(li)