

一个正在运行的Linux容器
- 一组联合挂载在/var/lib/docker/aufs/mnt上的rootfs,也就是"容器镜像",容器的静态视图
- 一个由Namespace+Cgroup构成的隔离环境,这一部分称为"容器运行时",容器的动态视图
真正承载着容器信息进行传递的,是容器镜像,而不是容器运行时
kubernetes的由来
- 核心特性都基于Borg/Omega系统的设计与经验
- 在开源社区落地过程中,修复了很多当年遗留在Borg体系中的缺陷和问题
架构图
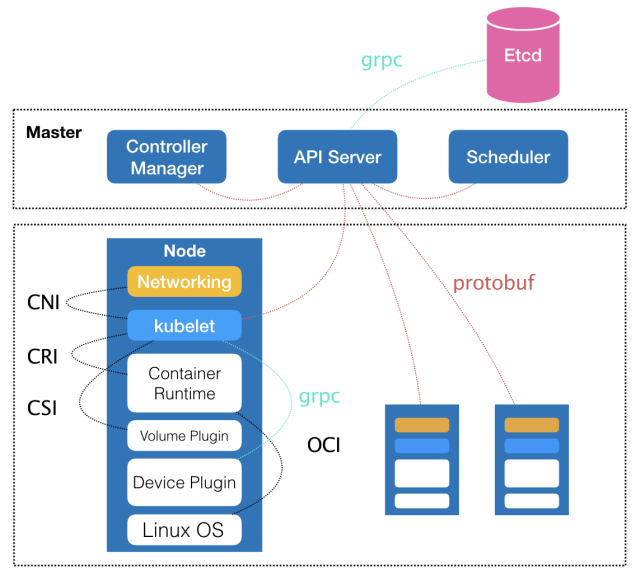
和原型项目Borg非常类似,都由Master和Node两种节点组成,分别对应着控制节点和计算节点
控制节点,Master节点
- 负责API服务的kube-apiserver
- 负责调度的kube-scheduler
- 负责容器编排的kube-controller-manager
- 整个集群的持久化数据,由kube-apiserver处理后保存在Etcd中
计算节点,Node节点
- kubelet主要负责和容器运行时打交道
- 而这个交互依赖的是CRI(Container Runtime Interface)的远程调用接口
- 这个接口定义了容器运行时的各项核心操作,比如启动一个容器所需要的所有参数
- 不需要关心是什么容器运行时,用到的什么基础
- 只要这个容器能够运行标准的容器镜像,他就可以通过实现CRI接入到kubernetes项目当中
容器运行时
- 例如Docker项目,一般通过OCI这个容器运行时规范通底层的Linux操作系统进行交互
- 即:把CRI请求翻译成对Linux操作系统的调用(操作Linux Namespace和Cgroups等)
kubelet
- kubelet还通过gRPC协议同一个叫做Device Plugin的插件进行交互
- 这个插件是Kubernetes项目用来管理GPU等宿主机物理机设备的主要组件
- 也是基于kubernetes项目进行机器学习,高性能作业支持等工作必须关注的功能
- 调用网络插件和存储插件为容器配置网络和持久化存储
- 这两个插件和kubelet交互的接口,分别是CNI(Container Networking Interface)和CSI(Container Storage Interface)
Borg项目对kubernetes的指导作用
- 体现在Master节点之上
- 虽然在Master实现的细节上和Borg有所不同
- 但是出发点却高度一致:即如何编排,管理,调用用户提交的作业
- 将Docker仅仅作为最底层的一个容器运行时实现
- 着重解决的问题:运行在大规模集群中的各种任务之间,实际上存在着各种各样的关系
- 处理这些关系,才是作业编排和管理系统最困难的地方
kubernetes项目最主要的设计思想
从宏观的角度,以统一的方式来定义任务之间的各种关系,并且为将来支持更多种类的关系留有余地
紧密关系的应用
- 这些应用之间需要非常频繁的交互和访问,或者直接通过本地文件系统进行信息交换
- 在常规环境下,这些应用往往会直接部署在同一台机器上,通过localhost通信,通过本地磁盘交换文件
- 但在kubernetes项目中,这些容器会被划分为一个Pod
- Pod里的容器共享同一个Network Namespace ,同一数据卷,从而达到高效交换信息的目的
类似Web应用和数据库之间的访问关系
- kubernetes提供了一种叫做Service的服务
- 给Pod绑定一个Service服务,而Service服务声明的IP地址等信息是终生不变的
- 这个Service服务的主要作用,就是作为Pod的代理入口
- 从而代替Pod对外暴露一个固定的网络地址
Secret对象
- 其实是保存在Etcd里的键值对数据
- 可以把Credential信息以Secret的方式存在Etcd里
- kubernetes就会在你指定的Pod启动时,自动把Secret里的数据以Volume的方式挂载刀片容器里
kubernetes的推崇做法
- 通过一个"编排对象",比如PodmJob,CronJob等,来描述你试图管理的应用
- 再为它定义一些"服务对象",比如Service,Secret, HPA等.这些对象会负责具体的平台级功能
